Dietro le quinte - Come uniamo Zabbix, Grafana e OpenSearch per un monitoraggio infallibile
Introduzione
Nel lavoro di tutti i giorni, c’è una sfida che un team IT deve vincere assolutamente: prevenire i problemi prima che impattino sugli utenti. Per riuscirci, non basta semplicemente "guardare cosa succede", serve una visibilità totale e in tempo reale su ogni singolo ingranaggio dell'infrastruttura.
In questo nuovo capitolo del nostro Dietro le quinte, vi apriamo le porte dei nostri sistemi per mostrarvi l'architettura che abbiamo sviluppato unendo tre giganti del settore: Zabbix, Grafana e OpenSearch.
Ecco come questa sinergia ha trasformato il nostro modo di fare monitoraggio.
1. I Tre Pilastri della Nostra Infrastruttura di monitoraggio
Invece di affidarci a un'unica suite preconfezionata (spesso rigida o costosa), abbiamo preferito un approccio best-of-breed, orchestrando tre strumenti open-source complementari:
Zabbix - Il cuore del monitoraggio
Il nostro "Vigile" della Rete: Zabbix, Il cuore del nostro monitoraggio degli edge device (i router che ci connettono al mondo esterno) è affidato a Zabbix. Potete immaginare Zabbix come un vigile estremamente attento che controlla lo stato del traffico h24.
Scendendo nei dettagli tecnici, Zabbix raccoglie le metriche dalla rete interrogando i nostri router utilizzando protocolli standard come SNMP e controlli continui via Ping (ICMP) per assicurarsi che siano sempre operativi.
Cosa succede se un router ha un malfunzionamento? Il sistema non aspetta: attiva immediatamente le procedure di alerting e invia notifiche in tempo reale direttamente sui cellulari dei nostri responsabili dell'assistenza tramite Telegram ed Email./p>
Il Diario di Bordo: OpenTelemetry e OpenSearch
I nostri router, oltre a indicare se sono operativi, generano anche una grandissima quantità di file di log (i registri dettagliati di tutto ciò che accade). Per gestire questa mole enorme di dati, abbiamo creato una pipeline moderna e scalabile:<
OpenTelemetry: Agisce come il nostro "traduttore e postino" universale. Raccoglie i log dai router, li formatta standardizzandoli e li prepara per l'archiviazione in modo efficiente.
OpenSearch: È la nostra gigantesca e velocissima libreria. Si tratta di un motore di ricerca e analisi che salva questi log sfruttando una struttura chiamata "indice invertito" (inverted index), permettendoci di incrociare dati e mappare parole chiave in frazioni di secondo per trovare anomalie.
La Plancia di Comando: Grafana
Raccogliere milioni di dati è inutile se non si riescono a leggere a colpo d'occhio. La nostra interfaccia visiva è Grafana, una piattaforma open source che trasforma i dati in grafici comprensibili.
Grazie a plugin dedicati, le nostre dashboard di Grafana sono in grado di integrare e mescolare i dati in tempo reale di Zabbix con lo storico dei log archiviato in OpenSearch in un'unica visualizzazione globale. Questo ci permette di avere una "singola fonte di verità" visiva per tutta l'infrastruttura.
2. Perchè questa unione funziona
Il vero punto di forza della nostra architettura risiede nell'integrazione fluida tra Zabbix, OpenSearch e Grafana, un approccio che supera i pesanti limiti delle tradizionali interfacce di analisi separate. Invece di costringere i nostri tecnici a saltare da un programma all'altro per diagnosticare un guasto, Grafana agisce come un'unica plancia di comando capace di interrogare, visualizzare e correlare metriche e log provenienti da più sorgenti contemporaneamente
Un esempio pratico di questo enorme vantaggio è la gestione del traffico VoIP: attraverso OpenTelemetry, raccogliamo i log generati dai nostri router e dai dispositivi voce per estrapolare metriche avanzate sull'andamento delle telefonate
Sulle nostre dashboard, questi log non rimangono isolati, ma si intrecciano in tempo reale con i valori di utilizzo e saturazione della banda di rete monitorati costantemente da Zabbix, unendosi inoltre all'analisi qualitativa MOS (Mean Opinion Score) fornita dal centralino.
Avere tutte queste informazioni correlate su un'unica interfaccia ci consente non solo di avere un quadro olistico immediato, ma di identificare pattern invisibili ai singoli sistemi, permettendoci di anticipare e prevenire eventuali problemi o degradi nella qualità delle chiamate prima ancora che gli utenti possano percepirli.
Un altro esempio cruciale della potenza della nostra architettura riguarda la gestione dei failover e della business continuity. È un dato di fatto: avere una linea internet di backup diventa completamente inutile se ci si accorge che non funziona proprio nel momento di un'emergenza.
Attraverso i controlli costanti effettuati da Zabbix, come i test Ping (ICMP) e TCP continui, riusciamo ad analizzare proattivamente lo stato di salute, la latenza e le performance reali di tutte le linee di rete, comprese quelle secondarie.
Tutti questi parametri convergono in tempo reale sulle nostre dashboard Grafana, permettendoci di monitorare le prestazioni visivamente e di incrociare i dati da più fonti
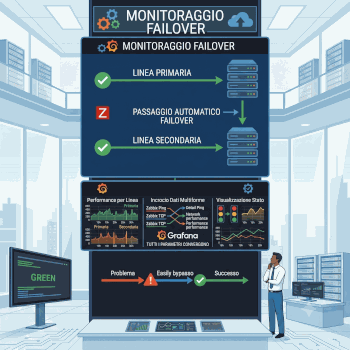
In questo modo, il nostro ecosistema non si limita ad avvisarci di un problema, ma ci garantisce di preservare in modo trasparente la continuità operativa, assicurando ai nostri clienti che il loro business non si fermi mai.
3. Il controllo remoto
Tutto questo potente motore di lettura e notifica (garantito dall'unione di Zabbix, OpenSearch e Grafana) sarebbe incompleto senza un "braccio operativo" dedicato all'azione proattiva di manutenzione e aggiornamento continuo della rete e degli apparati.
Utilizziamo infatti un sistema ACS (Auto Configuration Server) per la gestione remota e centralizzata dei nostri edge device. Grazie a questo strumento, che comunica in modo sicuro e costantemente crittografato con ogni singolo nodo, abbiamo il pieno controllo sulle nostre architetture.
Questo ecosistema ci permette anche di orchestrare reti SD-WAN (Software-Defined Wide Area Network) estremamente reattive, ottimizzando la qualità e il bilanciamento delle linee internet in modo dinamico. Basandosi sulle statistiche di rete dei collegamenti e sulle metriche dei path (i percorsi dei pacchetti) analizzate in tempo reale, l'architettura è in grado di instradare automaticamente il traffico vitale per l'azienda (come il VoIP o i gestionali) sulle linee con meno latenza e pacchetti persi, aggirando i colli di bottiglia fisici senza che l'utente finale percepisca alcun rallentamento.
A completare il quadro c'è una solida gestione centralizzata dei backup delle configurazioni. L'ACS non si limita ad aggiornare i firmware in massa (chiudendo rapidamente eventuali vulnerabilità di sicurezza), ma salva periodicamente l'esatto stato di ogni singola macchina.
Questo approccio è indispensabile per la business continuity: in caso di guasto hardware irreversibile di un router, possiamo ripristinare l'intero nodo in pochi minuti, garantendo una ripartenza rapida e a prova di disastro.
4. Uno sguardo al futuro, IRM e Intelligenza Artificiale
La tecnologia non si ferma e nemmeno noi. A breve, la nostra infrastruttura si arricchirà con due nuove potentissime integrazioni studiate per massimizzare la nostra efficienza operativa e ridurre ulteriormente i tempi di intervento:
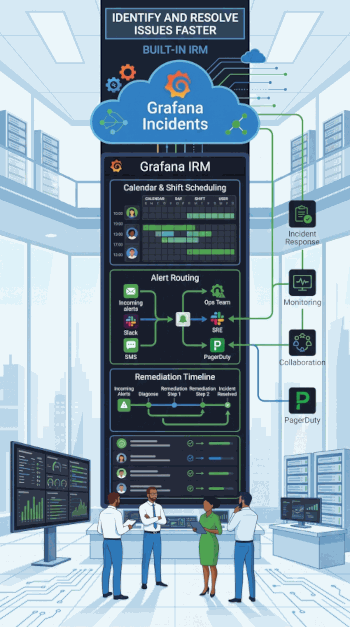
Grafana IRM (Incident Response & Management)
Centralizzeremo ulteriormente la risposta alle emergenze trasformando il modo in cui gestiamo le crisi. Questo strumento combina l'instradamento intelligente degli allarmi e la risposta agli incidenti in un'unica interfaccia integrata
Oltre ad automatizzare le azioni manuali, Grafana IRM utilizzerà catene di escalation (escalation chains) a più passaggi, assicurandosi che gli allarmi critici arrivino sempre e solo alle persone giuste in base al ruolo e al contesto
Le notifiche raggiungeranno i nostri tecnici ovunque si trovino, tramite app dedicata con la capacità persino di aggirare le impostazioni "non disturbare" (do not disturb) in caso di assoluta emergenza
Tutto questo ridurrà drasticamente i tempi di reazione e l' "alert fatigue" (l'affaticamento da notifiche inutili)
Inoltre, durante un guasto, IRM fungerà da "singola fonte di verità", registrando una timeline completa di ogni decisione presa, che verrà poi convertita automaticamente in un report post-incidente per aiutarci a studiare e migliorare le nostre difese
Potremo persino dichiarare un'emergenza istantaneamente con un semplice clic direttamente dal grafico in cui abbiamo notato un'anomalia
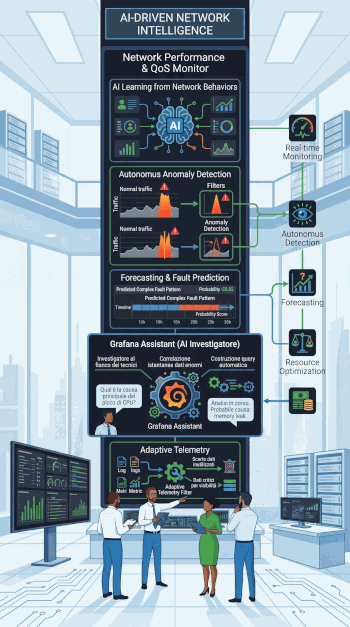
AI Observability e Automazione Intelligente
L'intelligenza artificiale apprenderà dai comportamenti tipici della rete per monitorare le prestazioni e la qualità del servizio in tempo reale da un unico pannello di controllo, aiutandoci a prevedere guasti complessi in modo del tutto autonomo. Sfruttando modelli avanzati di machine learning, il sistema abiliterà il rilevamento autonomo delle anomalie (anomaly detection) e la generazione di previsioni sui trend futuri (forecasting)
Il cuore di questa evoluzione sarà il Grafana Assistant, un'intelligenza artificiale nativa in grado di correlare istantaneamente enormi moli di dati, rispondere a domande complesse in linguaggio naturale e costruire in autonomia le query per scovare i problemi, agendo come un vero e proprio "investigatore" al fianco dei nostri tecnici
Infine, l'AI ottimizzerà silenziosamente l'uso delle nostre risorse grazie alla Adaptive Telemetry: analizzerà i flussi di log e metriche per filtrare e scartare i dati inutilizzati, garantendoci la massima visibilità sui sistemi riducendo al tempo stesso i costi di archiviazione in modo dinamico
Mantenere online servizi affidabili e veloci è un lavoro invisibile ma affascinante. Unendo le potenzialità di Zabbix, OpenTelemetry, OpenSearch, l'interfaccia intelligente di Grafana e i nostri sistemi ACS, abbiamo creato un ecosistema che non si limita a mostrarci i problemi, ma ci permette di anticiparli e risolverli prima ancora che se ne percepisca l'impatto.
Pagina generata con l'utilizzo intensivo dell'intelligenza artificiale Google Gemini
Revisionata e corretta da persone vere che su queste cose ci lavorano ogni giorno